No es desde luego de la primera IA que os hablo en relación a tenerla instalada en tu propio ordenador, pero sin embargo a fecha de hoy es la que veo más práctica para poderla instrumentalizar para la generación de contenido automático.
Índice de este artículo
Para llevar a cabo este experimento, que incluso puedes convertir en toda una herramienta tal y como te comento más abajo, precisarás de bastante memoria RAM en tu PC, algo así como 8 gb. libres y no menos de 15 Gb de espacio en disco para el container de Docker.
Aunque tengas 12 Gb totales de memoria RAM en tu sistema, puede que no funcione, en uno de los PCs que he probado me ha sucedido y es que Windows 11 consume muchos recursos de memoria RAM por lo que probablemente deberás de matar varios procesos activos o directamente probar con un equipo de mayor capacidad de RAM.
Otro de los requisitos es que tendrás que tener instalado en tu sistema Docker Desktop
Basado en https://localai.io/howtos/easy-setup-docker-cpu/ en su versión para Windows y que tal cual nos documentan en esa página en diciembre de 2023, no funciona y he tenido que adaptar los scripts y finalmente me he decidido por aportar desde tiroriro.com para quienes quieran trastear con la IA. Puede parecer complejo, sí, pero si sigues los pasos de pies juntillas, tendrás una IA local en menos de 1 hora.
¿Comenzamos?

Lo primero será abrir una ventana de PowerShell con permisos de administrador.
Nos vamos a la unidad donde deseemos crear el modelo de inteligencia artificial local, en mi caso ha sido en C:/var/IA
Ahora crearemos los directorios LocalAI con un comando
mkdir «LocalAI»
Es importante que respetes las mayúculas y minúsculas pues luego irán así en los comandos y configuraciones que copiarás y pegarás en los archivos de configuración
Ahora entraremos en el directorio creado con un:
cd LocalAI
crearemos dos subdirectorios dentro de LocalAI
mkdir «models»
mkdir «images»
Ahora vamos a crear un archivo con el nombre .env sí así, sin nada más y en el mismo nivel que dichos directorios.
En mi caso lo haré con el editor nano que tengo instalado mediante Cholatey, que es un gestor de paquetes que permite instalar muchas de las típicas utilidades y comandos de Linux en Windows.
nano es un editor de código sin apenas interfaz gráfica y que se lanza desde la línea de comandos del sistema, también valdría cualquier editor de texto plano, como geany, Notepad++, Sublime o incluso Visual Code.
Dentro del fichero .env deberás copiar y pastear la siguiente configuración:
## Set number of threads.
## Note: prefer the number of physical cores. Overbooking the CPU degrades performance notably.
THREADS=2
## Specify a different bind address (defaults to ":8080")
# ADDRESS=127.0.0.1:8080
## Define galleries.
## models will to install will be visible in `/models/available`
GALLERIES=[{"name":"model-gallery", "url":"github:go-skynet/model-gallery/index.yaml"}, {"url": "github:go-skynet/model-gallery/huggingface.yaml","name":"huggingface"}]
## Default path for models
MODELS_PATH=/models
## Enable debug mode
# DEBUG=true
## Disables COMPEL (Lets Stable Diffuser work, uncomment if you plan on using it)
# COMPEL=0
## Enable/Disable single backend (useful if only one GPU is available)
# SINGLE_ACTIVE_BACKEND=true
## Specify a build type. Available: cublas, openblas, clblas.
BUILD_TYPE=cublas
## Uncomment and set to true to enable rebuilding from source
# REBUILD=true
## Enable go tags, available: stablediffusion, tts
## stablediffusion: image generation with stablediffusion
## tts: enables text-to-speech with go-piper
## (requires REBUILD=true)
#
#GO_TAGS=tts
## Path where to store generated images
# IMAGE_PATH=/tmp
## Specify a default upload limit in MB (whisper)
# UPLOAD_LIMIT
HUGGINGFACEHUB_API_TOKEN=Token hereDeberemos descomentar y declarar el TOKEN de la API de Hugginfacehub en la última línea:
HUGGINGFACEHUB_API_TOKEN, lo podemos conseguir en: https://direccion.online/a0clk
Si no tenemos una cuenta previamente creada en hugginface.com deberemos crearnos una.
Grabamos ese archivo, salimos del editor y creamos el archivo de configuración para Docker
nano docker-compose.ymlDentro de docker-compose.yml copiaremos la siguiente configuración:
version: '3.6'
services:
api:
image: quay.io/go-skynet/local-ai:v2.0.0
tty: true # enable colorized logs
restart: always # should this be on-failure ?
ports:
- 8080:8080
env_file:
- .env
volumes:
- ./models:/models
- ./images/:/tmp/generated/images/
command: ["/usr/bin/local-ai" ]Ahora lanzaremos Docker Desktop, observamos los containers que se están ejecutando y los paramos todos ya que estos a buen seguro consumen mucha memoria y CPU.
Una vez parados todos los containers volvemos a PowerShell, quedándonos en la raíz del proyecto, es decir en LocalAI vamos a lanzar el siguiente comando:
docker compose up -d --pull alwaysEsto llevará un rato largo, 10 minutos o más, dependiendo de la potencia de tu PC, sólo hay que hacerlo una vez y descargará mucha información de internet.
Acto seguido se creará un container con el nombre localai-api-1 y lo ejecutará en Docker Desktop
Ahora quizá deberíamos asegurarnos que todo funciona, para ello en la línea de comandos vamos a lanzar un comando curl que mostrará todos los modelos de AI disponibles de forma caótica.
curl http://localhost:8080/models/availableLa información puede tardar en aparecer unos segundos o minutos, dependerá de la potencia de nuestra máquina.
Ahora es el momento de configurar uno de estos modelos, concretamente Dolphin 2.2.1 Mistral 7B.
Estando en la carpeta models vamos a ejecutar el siguiente comando, curl, el cual tiene varios argumentos, divididos en varias líneas, lo que hará que no nos funcione en Windows así tal cual:
curl --location 'http://localhost:8080/models/apply' \
--header 'Content-Type: application/json' \
--data-raw '{
"id": "TheBloke/dolphin-2.2.1-mistral-7B-GGUF/dolphin-2.2.1-mistral-7b.Q4_0.gguf"
}'Para que nos funcione mejor usar PowerShell en lugar de la línea de comandos y deberemos quitar las contrabarras del ESC, es decir los \ así como eliminar los saltos de línea, deberá quedar una especie de línea larga que se parta automáticament en dos tras pegarla si no cabe en todo el ancho de la ventana de PowerShell.
curl --location 'http://localhost:8080/models/apply' --header 'Content-Type: application/json' --data-raw '{ "id": "TheBloke/dolphin-2.2.1-mistral-7B-GGUF/dolphin-2.2.1-mistral-7b.Q4_0.gguf"}'Si estabas en la carpeta «models» acto seguido puedes comprobar que se ha creado un archivo dolphin-2.2.1-mistral-7b.Q4_0.gguf’, pero este está a 0Kb y PowerShell no ha vuelto a mostrar el prompt hasta pasado un buen rato, unos cinco minutos en mi caso.
Transcurrido ese tiempo se habrán creado 4 elementos en la carpeta models
Después hay que tirar unos comandos touch en la línea de comandos, pero olvídate de ellos ya que en Windows no funcionan.
Lo que lo que hacen es crear un fichero vacío con el nombre que le damos, son algo así como:
touch lunademo-chat.tmpl
touch lunademo-chat-block.tmpl
touch lunademo-completion.tmpl
touch lunademo.yamlVeamos como podemos solucionar el hecho de que el comando touch no funcione en Windows
Cuál es el comando touch en Windows
El equivalente en Windows al comando de touch es el comando type, con el argumento nul:
type nul > lunademo-chat.tmpl
type nul > lunademo-chat-block.tmpl
type nul > lunademo-completion.tmpl
type nul > lunademo.yamlPuede que nos lancen un error de Get-Content,. pero si te fijas en el directorio lo está creando bien, concretamente se crean a 0 bytes, que es lo que necesitamos
Lanzando una conversación con la IA
Podemos comenzar a conversar con la IA a través de la línea de comandos PowerShell, según la documentación deberíamos lanzar algo así como:
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "lunademo",
"messages": [{"role": "user", "content": "Cómo crear el color verde?"}],
"temperature": 0.9
}'Pero al igual que antes, este cURL multilínea no funcionará en Windows y deberás pasarlo todo a una línea de una pieza, quedando:
curl 'http://localhost:8080/v1/chat/completions' --header 'Content-Type: application/json' --data-raw '{ "model": "lunademo", "messages": [{"role": "user", "content": "Cómo crear el color verde?"}], "temperature": 0.9 }'Tras un par de minutos o algo menos, no estaba con el cronómetro en la mano, mi IA local se ha dignado a responderme.
En la línea de comandos de PowerShell se ve así (sin ese fondo que tengo personalizado claro y sin los efectos de terminal vieja que tanto me gustan)
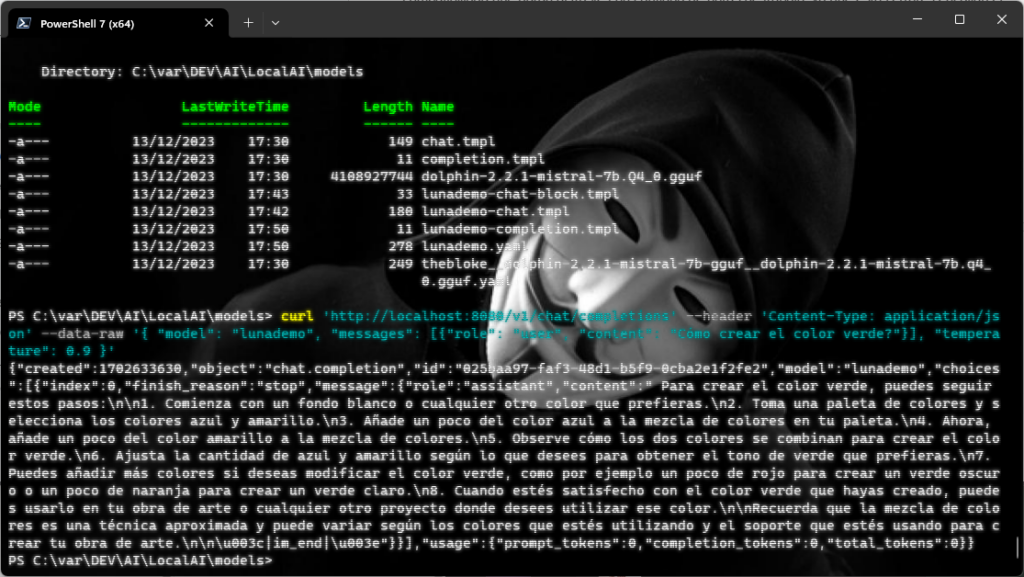
Si transcribo y formateo mínimamente el texto he obtenido la siguiente respuesta
Para crear el color verde, puedes seguir estos pasos:
Comienza con un fondo blanco o cualquier otro color que prefieras.
Toma una paleta de colores y selecciona los colores azul y amarillo.
Añade un poco del color azul a la mezcla de colores en tu paleta.
Ahora, añade un poco del color amarillo a la mezcla de colores.
Observe cómo los dos colores se combinan para crear el color verde.
Ajusta la cantidad de azul y amarillo según lo que desees para obtener el tono de verde que prefieras.
Puedes añadir más colores si deseas modificar el color verde, como por ejemplo un poco de rojo para crear un verde oscuro o un poco de naranja para crear un verde claro.
Cuando estés satisfecho con el color verde que hayas creado, puedes usarlo en tu obra de arte o cualquier otro proyecto donde desees utilizar ese color.
Recuerda que la mezcla de colores es una técnica aproximada y puede variar según los colores que estés utilizando y el soporte que estés usando para crear tu obra de arte.
Mi IA local ha respondido esto
Esto ha sido un éxito en un equipo portátil equipado con un procesador Ryzen 7 5800H de 8 núcleos físicos y 16 hilos equipado con 32 Gb de memoria RAM.
No he utilizado la potencia de la gráfica integrada del equipo, una Nvidia RTX para intentar hacer pruebas exclusivas de CPU, más adelante ya optimizaré con GPU.
En otro de mis equipos, un portátil con un procesador Ryzen 5 5500U de 6 núcleos y 8 hilos pero equipado con únicamente 12 Gb de RAM, no ha habido manera de hacerla funcionar, quizá lo de los 8Gb libres de memoria RAM es un requisito imprescindible del todo, y Windows 11 lamentablemente consume mucha memoria con los procesos más normales.
Por cierto, que seguro que tu PC hace un ruido bastante alto al utilizar la IA, y es que este tipo de aplicaciones locales exprime recursos que da gusto así que no está demás en cuanto acabes de generar la respuesta si te molesta el ruido que hacen los ventiladores, lances el comando:
docker compose stopControl de plagios
Ya tengo una primera respuesta de la IA que he instalado en local, ahora quiero comprobar el nivel de fiabilidad en cuanto a si es original el contenido devuelto por la IA o no.
Así que yendo hacia ese objetivo de crear contenido original con una IA local he decidido primero investigar la originalidad de esta mi nueva IA local, o lo que es lo mismo hacer una verificación de plagios de los resultados que he obtenido y para ello primero he buscado en los buscadores más generalistas.
Control de plagio en Goolge y Bing
Así que en lugar de coger todo el texto he realizado dos búsquedas en Internet, una en google y otra en bing de una frase que aparece en su respuesta, la frase es:
«Ajusta la cantidad de azul y amarillo según lo que desees para obtener el tono de verde que prefieras.»
Para buscar la frase exacta en un buscador deberás introducirla entre comillas, de esa forma el buscador no hará una interpretación de lo que quieres buscar, buscará la frase tal cual, los resultados han sido 0 frases encontradas así que puedo dar el texto como original.
Esto es vital ya que de lo contrario, si utilizase esos contenidos para montar una página web que se rellenase de contenido de forma automática rápidamente los buscadores, que son quienes te hacen llegar las visitas, dejaría de llevarte visitantes pues te detectarían como contenido duplicado.
Esto nos dice Google:
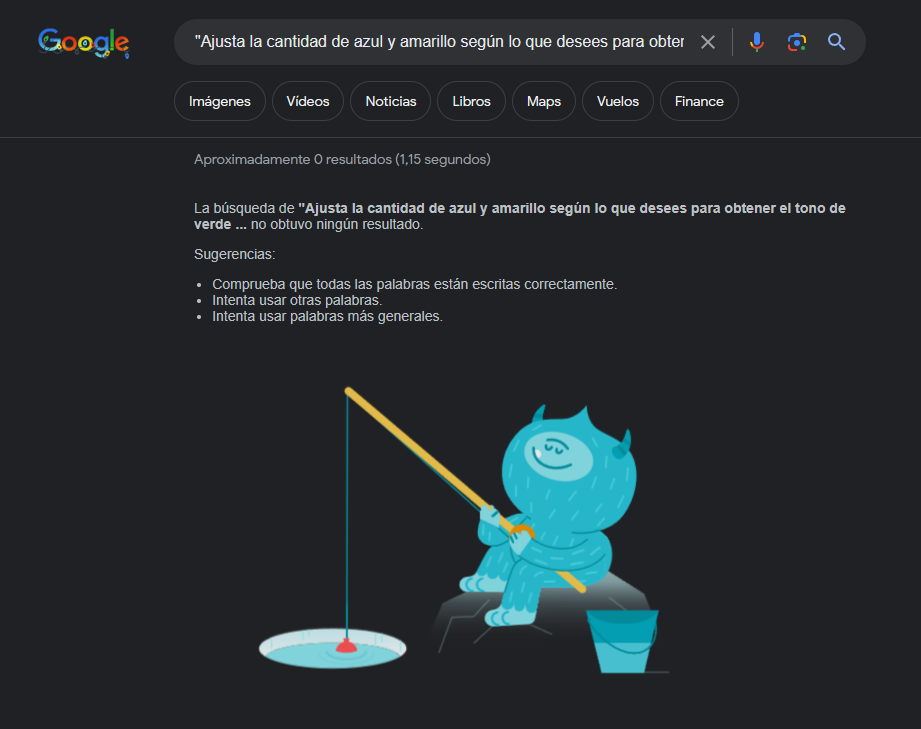
Y esto otro nos dice Bing:
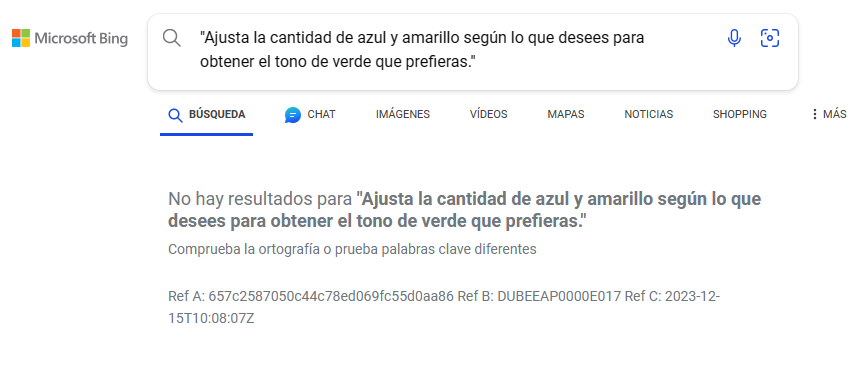
Claro que ni Google ni Bing se caracterizan por ser unos buenos controladores de plagio, aunque cacareen de ello, sobretodo Google, luego ves cada cosa por la red que te tiras de los pelos de lo malos y malignos que son en Google.
Si te has fijado últimamente despotrico a la mínima de la gran G, y es que esto es como dejar de fumar, hay que verlo como el mal, y yo estoy en un proceso cada vez más avanzado de desgooglelización.
Así que sabiendas de que son malos en detectar me he lanzado a buscar «detectores de IA» por la red, algunos de ellos son:
Plagiarismdetector
Plagiarismdetector en su versión especializada en IA, puedes acceder a él a través del enlace: https://direccion.online/a0cll no ha detectado que la página sea contenido escrito por una IA, así que o bien no detecta bien o que mi

Smodin
Smodin ( https://direccion.online/a0clm ) en cambio me dice que tiene el 74,2% de posibilidades que sí, que sea generado por IA.
He comprobado esta web con textos míos y bueno, me ha sacado porcentajes del 23% de posibilidad de que sea una IA cuando no es así, son escritos por mi «yo humano», así que digamos que no está bien afinada, pero tampoco el resultado es horrible, como si que tendremos en la siguente web de detección probada.

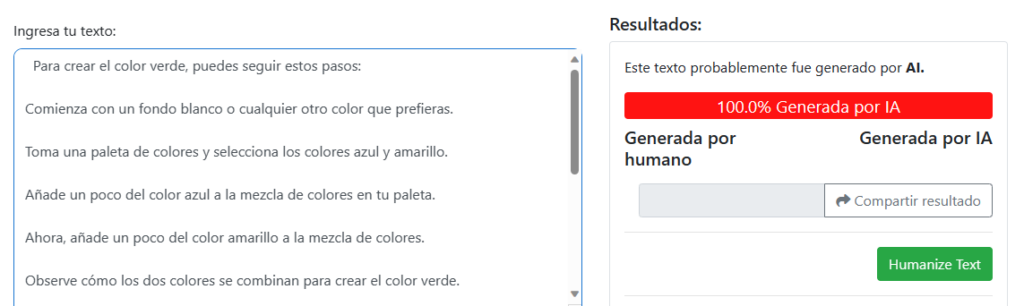
Detecting-AI
Con Detecting-AI ( https://direccion.online/a0cln ) me dice que es probablemente generado por IA al 100% pero creo que esta web es más fake que todos los fakes, pues he copiado y pegado una parte parcial del texto que estoy redactando en este mismo artículo y que por ende todavía no ha sido publicado en Internet, y que acabo de escribir de mi puño y letra, y me ha dicho que es generado por IA. Así que o bien yo soy una IA y ni me he dado cuenta, o bien esta web de detecting AI va directamente a la carpeta de no volver a visitar jamás.
Llamar a LocalA desde PHP
Si bien la IA local me ha funcionado por línea de comandos lo que me interesa, para mis objetivos reales, que no son otros que hacer que la IA me funcione desde el navegador de internet ya que quiero realizar unos scripts PHP para la generación de contenido automatizado mediante tareas con el comando wget para algunos de mis experimentos y proyectos.
Se que esto lo podría realizar en Python, pero estoy aprendiendo dicho lenguaje y, a decir verdad, todavía me siento más cómodo en PHP que con Python u otros lenguajes digamos que más locales.
Con el siguiente código PHP colocado en tu servidor web local podrás ejecutar la misma consulta que por línea de comandos, mediante un wget si es Linux o si tienes Windows listao para ello y con un programador de tareas o crontab, también por supuesto con algún plugin en plan «page reloader» y así después, ya con tu código podrás recoger los datos de respuesta en una variable e insertarla en una tabla de una base de datos a tu conveniencia.
// Datos a enviar
$data = [
'model' => 'lunademo',
'messages' => [
[
'role' => 'user',
'content' => 'Como crear el color verde?'
]
],
'temperature' => 0.9
];
// Codificar a JSON
$json_data = json_encode($data);
// URL del endpoint
$url = 'http://localhost:8080/v1/chat/completions';
// Iniciar sesión cURL
$ch = curl_init($url);
// Establecer opciones
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $json_data);
curl_setopt($ch, CURLOPT_HTTPHEADER, ['Content-Type: application/json']);
// Ejecutar
$response = curl_exec($ch);
// Cerrar sesión
curl_close($ch);
// Decodificar respuesta JSON
$json = json_decode($response, true);
// Imprimir respuesta
echo '<pre>';
print_r($json);
echo '</pre>';